User Guides
Résumé
Pour utiliser Label Studio, voici les principales étapes :
- Accédez à l'interface web de Label Studio
- Cliquez sur le bouton « Créer un projet »
- Configurez votre source et votre cible de stockage cloud.
- Choisissez le type de tâche d'annotation (par exemple, classification de texte, détection d'objets, etc.) et configurez les choix de labels.
Cette procédure décrit les actions pour déclarer dans labelStudio les projets et datasets pour qu'un utilisateur (traitant ou dataXX) puisse annoter les données des datasets qui lui sont affectés.
Prérequis
Une instance de label studio est créée notament pour une zone métier (voir le process de création d'une zone métier) mais il est possible d'instancier d'autres label studio pour des besoins ciblés pour une équipe, un projet, etc.
Lors de son instanciation, les groupes keycloak de l'instance sont automatiquement créés.
L'administrateur d'accès peut alors, dans GDA, donner l'accès à cette instance de labelStudio à tous ceux qui en ont besoin. Via GDA, il affecte les permissions d'accès pour cette instance :
- à l'administrateur données (celui qui va administrer cette instance : il pourra configurer les datasets)
- aux différents utilisateurs qui pourront annoter les datasets.
Créer un projet
Chaque projet contiendra ses propres données et ses consignes d'annotations.
Lorsque vous créez un projet, vous devez le configurer (settings):
- configurer les connexions de stockage d'entrée pour les données et de sortie pour l'annotation.
- l'interface d'annotation permet de choisir la manière dont vos annotateurs doivent procéder
Configurer les connexions des stockages
Généralités
Nous avons besoin d'un espace de stockage pour récupérer les données à annoter (source storage) et un espace de stockage pour entreposer les résultats d'annotation (Target storage).
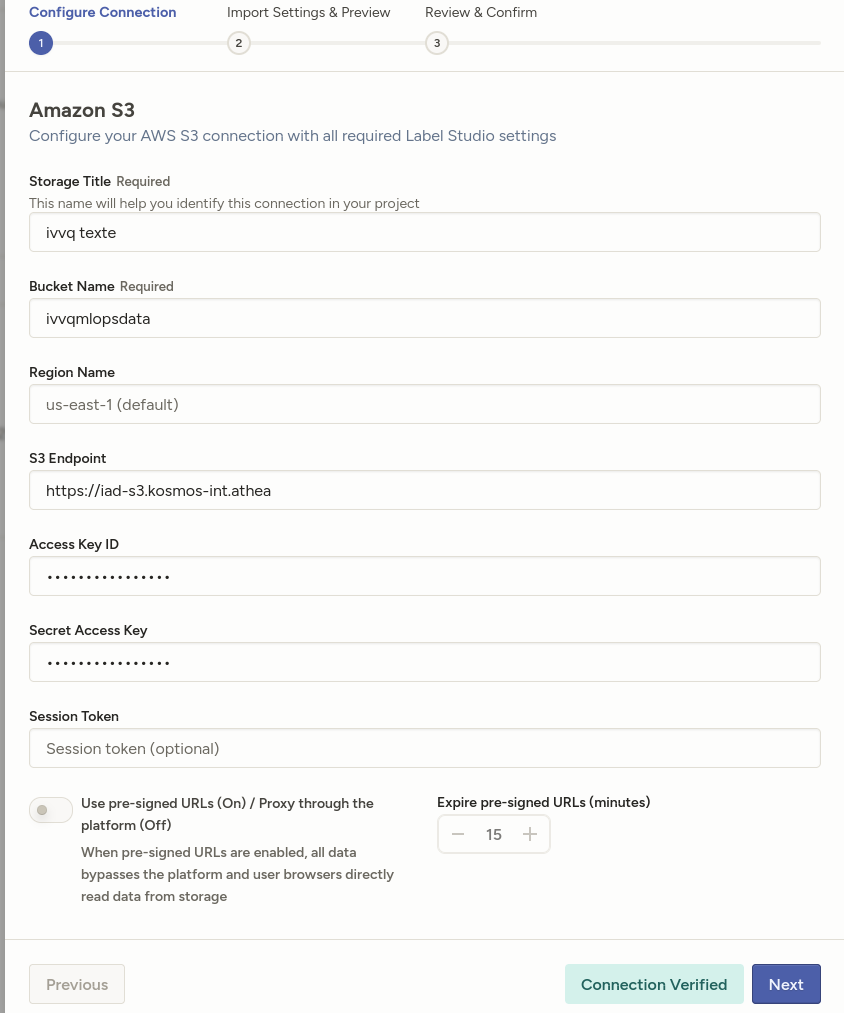
Par exemple, sélectionnez un stockage AWS S3
Points importants :
-
Point de terminaison S3 : Assurez-vous de saisir l’URL d’entrée avec le port d’entrée, car Label Studio y accédera via un navigateur.
-
Utiliser des URL pré-signées : Cette option n'est pas supportée dans tous les contextes. Elle peut être activée pour plus de sécurité. Elle génère une URL expirée offrant un accès aux objets privés sans exposer d’identifiants ni d’accès public. Il est recommandé de conserver la durée d’expiration par défaut.
-
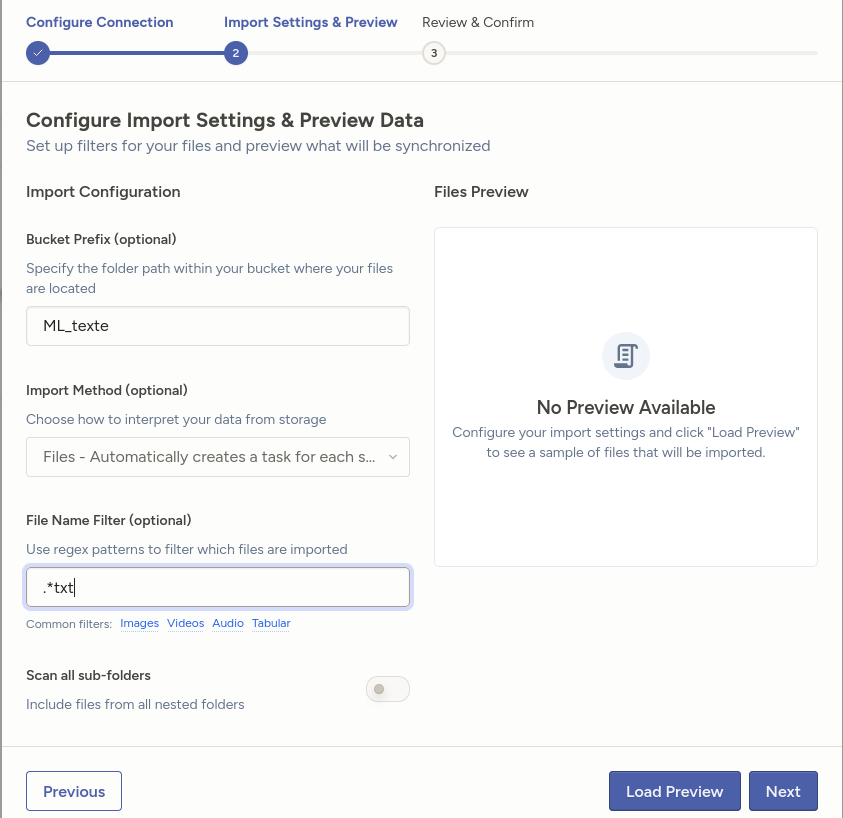
Import Method : Choisir "Files" pour que Label Studio génére automatiquement les tâches pour vos fichiers (comme les images, les video...) et les affichera automatiquement dans l’interface d’annotation. Si vous choisissez "Tasks", les fichiers non JSON, comme les images, généreront des erreurs, car Label Studio attend exclusivement des manifestes JSON décrivant les tâches (vous devrez alors manuellement créer des fichiers json décrivant les taches).
-
Expression régulière du filtre de fichiers : Ceci est important, car si Label Studio analyse un fichier JSON invalide, une erreur sera générée lors de la synchronisation.
Utiliser un EDS du socle
L'Administrateur données (qui a les droits pour gérer les compte techniques des EDS) configure l'instance de labelStudio.
Les données d'un dataset à annoter sont stockées dans un EdS s3 (bac à sable ou production). Les annotations sont elles aussi stockées (écrites) dans un EdS s3 (bac a sable uniquement puisque l'on écrit les annotations depuis le bac a sable).
Si les données que l'on souhaite annoter sont celles d'un espace de stockage de production il est obligatoire d'avoir un EdS Bac à sable pour écrire les annotations. Si les données que l'on souhaite annoter sont celles d'un espace de stockage du bac à sable, il est possible d'utiliser l'EdS contenant les données pour y déposer les annotations.
Comptes d'accès aux EdS
L'Administrateur données accède à l'outil EdS pour créer les compte d'accès à utiliser pour configurer l'accès à l'EdS dans labelStudio (configurer le dataset).
Il obtient les informations edsuser, password à utiliser ensuite dans labelStudio.
Si une politique BeC existe sur les données de l'EdS qui doivent être annotées, un matricule doit être concaténé au champ edsuser obtenu. Le matricule peut être celui d'un utilisateur existant ou artificiellement créé pour porter les attributs de sécurité souhaités : ces attributs seront ceux appliqués par la politique BeC de l'EDS et sera appliquée quelque soit l'utilisateur qui accède aux données via le dataset labelStudio.
Il configure le projet pour les accès aux EdS s3 : projet / settings / cloud Storage
Il ajoute les datasets nécessaires (source pour les données et target pour les annotations) en spécifiant les paramètres :
- endpoint =
https://iad-s3.technique.artemis(cas général) : modifier l'URL selon ce qui vous a été communiqué par votre Administrateur système - access key = edsuser = obtenu précédemment pour l'EdS (avec ou sans matricule)
- secret key = password obtenu précédemment pour l'EdS
Points à surveiller :
- Ne PAS Utiliser des URL présignées (non compatible avec le endpoint de l'IAD s3).
Annotation
Consignes d'annotation
Accéder aux "settings" / "labeling Interface".
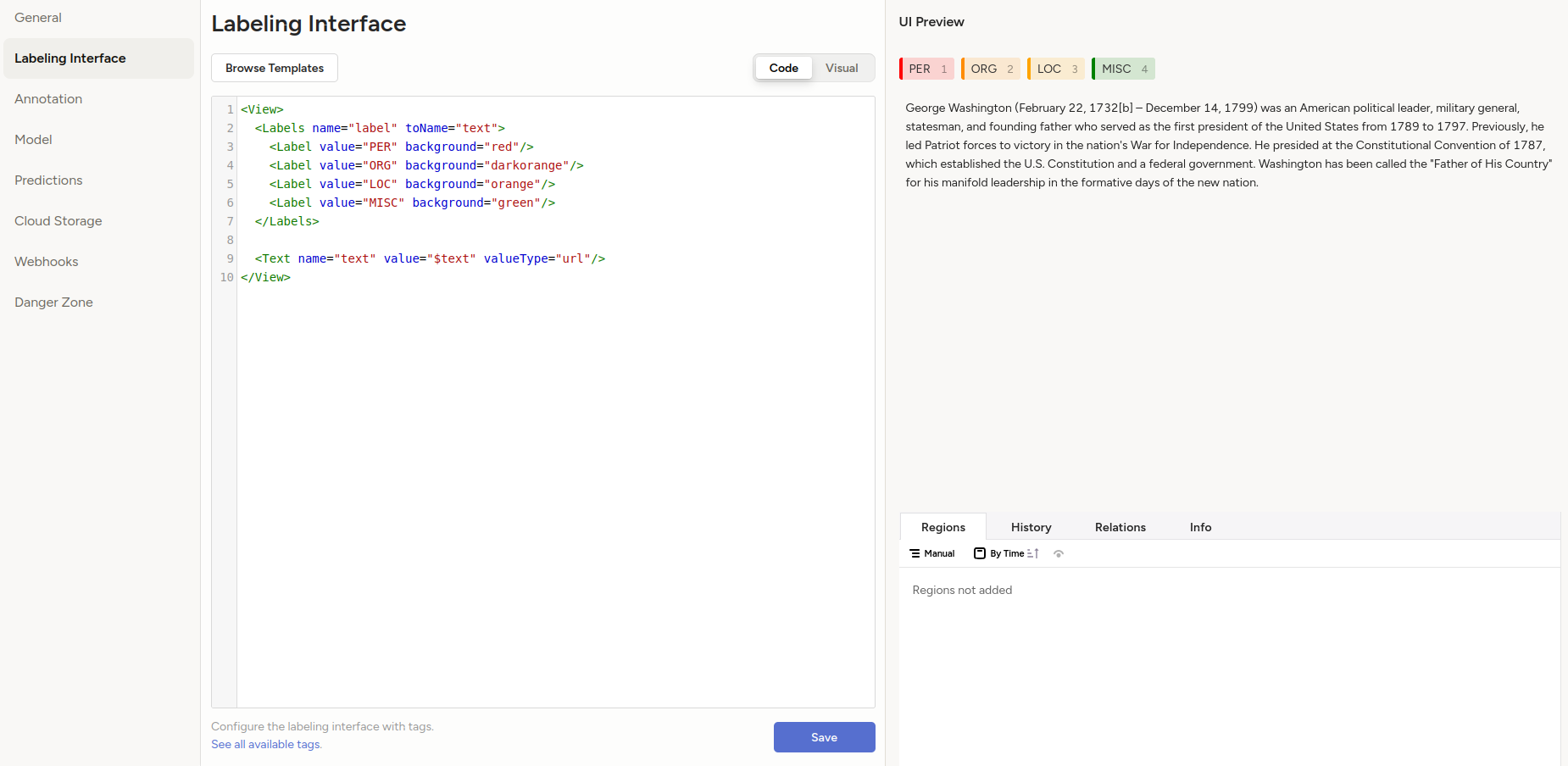
Choisir parmi les modèles "Browse Templates" le plus proche de ce que nous souhaitons faire.
Prenons l'exemple de la reconnaissance d'entités nommées. (choisir "Traitement du langage naturel > Reconnaissance d'entités nommées").
L'interface d'annotation déjà configurée pour la reconnaissance d'entités nommées est ouverte à une configuration plus poussée.
Modifiez les couleurs et les valeurs de vos étiquettes.
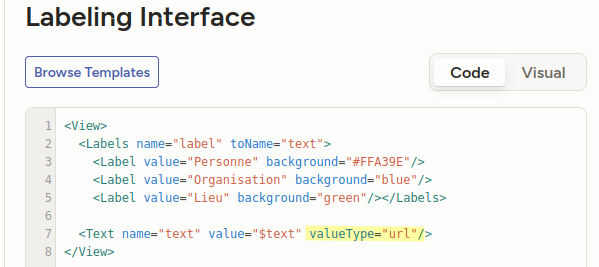
Important Si vous devez traiter des données sous forme d'URL S3, vous devez les configurer. Dans la vue de configuration déjà ouverte, cliquez sur Code pour pouvoir
modifier directement le code source de l'interface. Dans la balise Text, vous devez ajouter le paramètre valueType="url".
Il n'est actuellement pas possible de prendre en charge simultanément le texte intégré et les URL. Par conséquent, l'ajout d'une tâche contenant du texte intégré affichera simplement une erreur pour cette tâche spécifique.
L'utilisateur annote les données
L'utilisateur accède à l'instance de labelStudio.
Il peut accéder au projet, consulte les données et réalise les annotations conformément aux consignes prévues par l'Administrateur données.
Si une politique BeC est active, il ne verra que les données autorisées par la politique pour l'utilisateur dont le matricule a été indiqué.
Cas particulier : Importation de tâches
Il s'agit du cas où les données à annoter sont déjà sous forme de tâches (Tasks).
Importation d'une tâche avec du texte intégré via l'interface utilisateur
Une fois votre projet créé, vous pouvez créer des tâches. Prenons l'exemple de fichiers texte nécessitant des annotations ; la logique est identique pour les images et autres contenus.
Par défaut, Label Studio attend du texte intégré dans votre fichier de tâche. Voici un exemple :
[
{
"data": {
"text": "Hello, this is my Lorem Ipsum"
}
}
]
Vous pouvez glisser-déposer ce fichier de tâche via l'interface utilisateur. Dans notre cas, il sera stocké sur S3. Si vous n'avez pas configuré la persistance, il sera enregistré sur le disque.
Il est déconseillé d'utiliser le mode intégré pour les fichiers binaires tels que les fichiers audio ou les images, car leur sérialisation en base64 génère des fichiers texte difficiles à traiter.
Importer une tâche avec une URL via l'interface utilisateur
Outre la saisie directe du texte à annoter, vous pouvez également ajouter une URL pour y faire référence, comme file://, http(s):// ou s3://.
Vous pouvez utiliser une tâche comme celle-ci :
- Text
- Image
- Audio
[
{
"data": {
"text": "s3://textfiles/file.txt"
}
}
]
[
{
"data": {
"image": "s3://images/img.jpg"
}
}
]
[
{
"data": {
"audio": "s3://audiofiles/audio.mp3"
}
}
]
L'utilisation d'une URL avec le protocole s3:// nécessite la configuration d'un stockage cloud source via Paramètres > Stockage cloud. Sa configuration est expliquée ci-dessous. Le navigateur se connectera alors au serveur Source Cloud Storage à l'aide de ces identifiants, mais sans spécifier le bucket ni le préfixe configurés dans la source. Il récupérera ensuite le contenu du fichier pour que l'utilisateur puisse l'annoter et l'afficher sur la page.
L'import de la tâche via l'interface utilisateur ou l'API lui attribuera un identifiant.
Importer une tâche à distance
Vous pouvez vous connecter à un stockage cloud dans les paramètres de chaque projet et spécifier les sources des tâches, ainsi que les destinations où les résultats de vos tâches d'annotation seront envoyés.
Lorsque vous ajoutez une nouvelle source de stockage (dans notre cas, un bucket MinIO), tous les fichiers de tâches reconnus sont ajoutés automatiquement. Vous pouvez utiliser un filtre d'expression régulière sur les fichiers à traiter ; tout fichier ne correspondant pas au filtre sera ignoré.
Si de nouveaux fichiers sont ajoutés ultérieurement à votre bucket, vous devrez cliquer manuellement sur le bouton « Synchroniser » ou utiliser manuellement l'API pour déclencher une action de synchronisation.
Il est important de noter que chaque fichier doit contenir une seule tâche, et non une liste de tâches comme dans l'exemple ci-dessus. Même s'il ne s'agit que d'une liste d'une seule tâche, Label Studio attend un dictionnaire JSON contenant cette unique tâche, comme celui-ci :
{
"data": {
"text": "s3://textfiles/file.txt"
}
}
Si un fichier correspondant au filtre est invalide, aucun fichier ne sera importé après la commande Sync. Les erreurs seront clairement indiquées et préciseront la clé de l'objet S3 à l'origine du problème.
Importer une tâche avec des pré-annotations
Il est parfois nécessaire d'importer des données déjà annotées afin de permettre à l'utilisateur de les corriger ou de les améliorer. Dans ce cas, notre fichier JSON de tâche doit déjà inclure les annotations.
Voici un exemple de ce à quoi il devrait ressembler :
[
{
"data": {
"text": "Enter your text here"
},
"predictions": [
{
"result": [
{
"from_name": "label",
"to_name": "text",
"type": "labels",
"value": {
"start": 0,
"end": 4,
"labels": ["Verb"]
}
},
{
"from_name": "label",
"to_name": "text",
"type": "labels",
"value": {
"start": 11,
"end": 14,
"labels": ["Noun"]
}
}
]
}
]
}
]
Sortie de la tâche d'annotation
Une fois la tâche d'annotation terminée, L'annotateur peut soumettre l'annotation. Le résultat est enregistré dans la table PostgreSQL propre à labelStudio task_completion. Un rapport peut être généré.
Si votre projet dispose d'un bucket cible configuré via Paramètres > Stockage cloud > Stockage cloud cible, le rapport sera généré et enregistré automatiquement.
Chaque tâche génère un rapport au format JSON minifié, dont le nom correspond à l'ID de la tâche.
Le résultat de la tâche contient uniquement les indices de début et de fin de la sous-chaîne de l'annotation, les étiquettes qui leur ont été attribuées, ainsi que le chemin d'accès identique à celui du fichier task.json d'origine.
Voici un exemple du rapport généré :
export.json
{
"id": 106,
"result": [
{
"value": {
"start": 0,
"end": 76,
"labels": [
"Privacy"
]
},
"id": "7QKoXPWzTO",
"from_name": "labels",
"to_name": "text",
"type": "labels",
"origin": "manual"
},
{
"value": {
"start": 392,
"end": 822,
"labels": [
"Accountability"
]
},
"id": "-YOm2u2zqd",
"from_name": "labels",
"to_name": "text",
"type": "labels",
"origin": "manual"
}
],
"created_username": " admin@localhost, 1",
"created_ago": "0 minutes",
"completed_by": {
"id": 1,
"first_name": "",
"last_name": "",
"email": "admin@localhost"
},
"task": {
"id": 109,
"data": {
"text": "s3://textfiles/file.txt"
},
"meta": {},
"created_at": "2024-10-02T14:32:21.440188Z",
"updated_at": "2024-10-02T14:32:21.440216Z",
"is_labeled": true,
"overlap": 1,
"inner_id": 109,
"total_annotations": 1,
"cancelled_annotations": 0,
"total_predictions": 0,
"comment_count": 0,
"unresolved_comment_count": 0,
"last_comment_updated_at": null,
"project": 2,
"updated_by": null,
"file_upload": 5,
"comment_authors": []
},
"was_cancelled": false,
"ground_truth": false,
"created_at": "2024-10-02T14:35:10.454111Z",
"updated_at": "2024-10-02T14:35:10.454132Z",
"draft_created_at": "2024-10-02T14:35:09.248094Z",
"lead_time": 9.608,
"import_id": null,
"last_action": null,
"project": 2,
"updated_by": 1,
"parent_prediction": null,
"parent_annotation": null,
"last_created_by": null
}
Outre le rapport enregistré, vous pouvez générer un rapport pour chaque tâche terminée via l'interface utilisateur ou l'API.
Générer des annotations automatiquement
Configurer un modèle pour l'annotation automatique
Vous devez d'abord créer et déployer le modèle en respectant le format attendu par Label Studio.
Consultez cette documentation.
Vous pourrez ensuite l'utiliser.
Références
- Documentation officielle de Label Studio : https://labelstud.io
- Dépôt GitHub : https://github.com/heartexlabs/label-studio
- Référence de l’API Label Studio : https://labelstud.io/guide/api.html
- Label Studio pour l’apprentissage automatique : https://labelstud.io/guide/usage.html